Why MMM Evidence Is Citation Bait for AI Search Engines
The Sentence Shape That Gets Cited
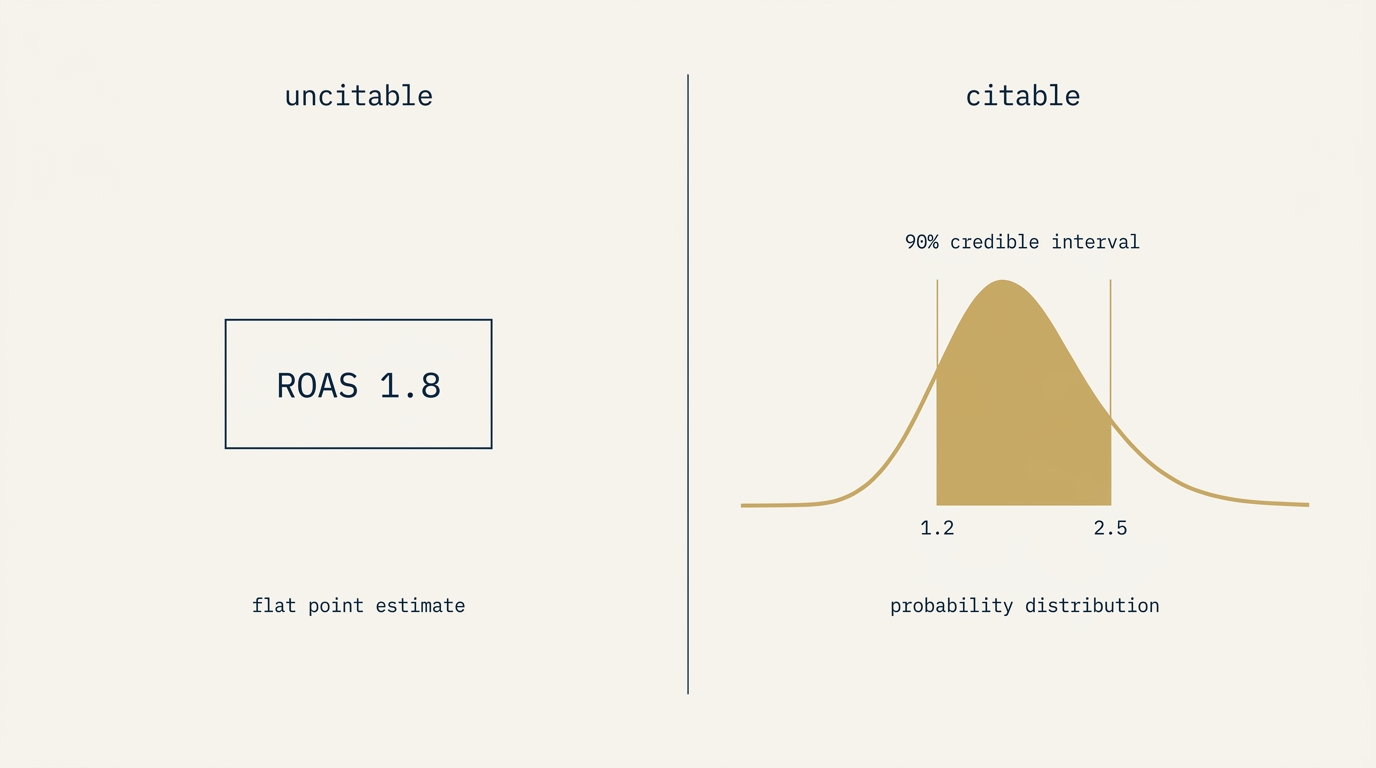
Bayesian marketing mix modeling produces a sentence shape that AI search engines preferentially cite. A statement like “TV ROAS sits between 1.2x and 2.5x with 90% probability” carries its own evidence boundary inside the sentence. The point-estimate equivalent, “TV ROAS is 1.8,” reads as an unsupported assertion. When an LLM is asked about TV ROAS in B2B finance, the first sentence gets quoted; the second gets either refused or rounded into a vague approximation.
The shape determines whether your measurement evidence is citation worthy or invisible. This is the first post in a ten-post thread arguing that Bayesian MMM is structurally well suited for AI search citation, and that most of the work to capture that advantage is not modeling work. It is publishing work.
What LLMs Cite, and What They Refuse To Cite
AI search engines face a structural problem with quantitative claims. They are accountable to users for accuracy and brand safe by design. A point estimate without a stated boundary is high risk to cite: any small error in the number propagates into the user-facing answer with no signal about how much trust to attach. The engines respond to this risk in one of three ways.
They refuse to characterize (“I cannot confirm that figure”). They cite the source domain without quoting the number (“according to a recent analysis”). Or they round the number into an attributed approximation that strips precision (“around 2x according to some analyses”).
Quantitative claims with explicit confidence bounds avoid all three failure modes. “TV ROAS sits between 1.2x and 2.5x with 90% probability” can be quoted verbatim with the boundary preserved. The engine inherits the source’s uncertainty rather than manufacturing its own. The result is reliable citation rather than evasion. This is the citation behavior pattern Bayesian MMM happens to feed naturally.
Three Properties That Map To AAO Gates
Bayesian MMM output has three structural properties that map cleanly onto the DSCRI ARGDW framework gates, and they compound in citation behavior.
Causal framing maps to the Content gate
The Content gate measures whether an extracted page passes the quality threshold for citation. The threshold is not about quality in a vague sense; it is about whether the page’s claims are structurally what the gate is designed to detect. Bayesian MMM is built around causal estimation. The output answers “if we cut TV spend by 30%, what happens to revenue” rather than “what is TV correlated with.” Causal claims are the highest-value content the Content gate detects, because they are the kind of statement a user actually wants to act on. Most published marketing content stops at correlation. Bayesian MMM stops at causation. The Content gate sorts the two.
Uncertainty quantification maps to the Structure gate
The Structure gate measures parseability. JSON LD and explicit confidence bounds both serve the same function: they make a claim quotable. A Bayesian credible interval is, in citation terms, a quotable unit. The bound is part of the claim, not a footnote. An LLM that extracts the bound preserves the analyst’s epistemic posture rather than inventing a new one. Bayesian MMM outputs are structurally a series of these quotable units. Every channel result, every budget recommendation, every counterfactual scenario comes packaged with its own boundary.
Methodology disclosure maps to the Differentiation gate
The Differentiation gate measures whether content is citation worthy versus replaceable. A blog post that says “TV works in finance” is replaceable by a thousand other posts that say the same. A Bayesian MMM analysis that documents its priors, adstock decay assumptions, and saturation parameters is not replaceable by another analysis with different assumptions; the methodology is the differentiator. Two firms running Bayesian MMM on the same channel will produce different posteriors because they used different priors, and the priors are themselves citable artifacts. AI engines weighting Differentiation will preferentially cite the analysis with explicit methodology over the one without.
What This Looks Like In Practice
Three concrete framings of the same underlying MMM result, rendered for LLM consumption:
-
The point estimate (uncitable): “Paid social ROAS is 2.1x in B2B finance.” The engine sees one number with no provenance and treats the entire claim as unverified. Cite probability: low.
-
The point estimate with confidence interval (partially citable): “Paid social ROAS is 2.1x with a 95% confidence interval of 1.6x to 2.7x in B2B finance.” Better. The interval gives the engine an anchor. But the form is statistical and the confidence-interval semantics (in long-run repetition, 95% of intervals would contain the true value) are not what users want to hear. Engines sometimes mangle the framing during extraction. Cite probability: moderate.
-
The Bayesian credible interval framing (citable): “Paid social ROAS sits between 1.6x and 2.7x with 95% probability in B2B finance.” Direct probabilistic statement. The engine quotes it intact because the form already matches how a user would interpret a citation. Cite probability: high.
The three framings come from the same underlying analysis. The choice between them is a publishing decision, not a modeling decision.
The Publishing Problem, Not The Modeling Problem
Most MMM teams ship results as analyst deliverables: a PDF, a slide deck, a login-gated dashboard. The model is correct. The output is rigorous. None of it is on the open web in a form an AI engine can extract. The team has done the analytical work and not done the publishing work, and the gap is where citation worthiness lives.
The publishing problem has three layers. First, does the output exist on a stable, addressable URL. Second, does the output include the structural elements (explicit probabilistic framing, methodology disclosure, source citations) that pass the AAO gates. Third, is the output linkable from other content that wants to cite it. Most MMM programs solve the first inadequately. Solving the second and third is the path from rigorous but invisible to rigorous and cited.
Worked Example
A B2B finance firm we audited ran a Bayesian MMM analysis quarterly. The model output was sound. Internal Slack channels and quarterly board decks referenced “TV ROAS of 1.8x, 90% credible interval 1.2x to 2.5x” routinely. Asked about TV ROAS in B2B finance, ChatGPT returned a refusal: “I cannot find authoritative data on TV ROAS in B2B finance.”
The diagnostic was straightforward. The firm had no public methodology page. The internal MMM reports were not indexed. The quarterly board decks were attached to internal documents that lived behind authentication. The firm’s blog discussed channel strategy in qualitative terms (“TV remains important for brand building”) with no reference to its MMM analysis. The model was world class. The publication chain did not exist.
The fix sequence: published a methodology page documenting model class, priors with source URLs, adstock and saturation parameterization, and validation approach; added BlogPosting plus Dataset schema; published one quarterly MMM digest blog post per quarter quoting credible-interval framings directly with internal links to the methodology page; added structured data to the methodology page with a stable URL.
Six weeks later, asked about TV ROAS in B2B finance, ChatGPT cited the firm’s methodology page and quoted the credible-interval framing verbatim. The model did not change. The publication chain did. Discovery, Structure, Content, and Differentiation gates all flipped from failing to passing in one publishing sprint.
What This Series Will Cover
This is post 1 of a ten-post thread on AAO + MMM, running Thursdays from Jul 2 through Sep 3 alongside the Tuesday thread on the ten DSCRI ARGDW gates. Subsequent posts develop specific tactics: cross-mapping MMM outputs against all ten AAO gates (post 2), the case for Bayesian over frequentist framing in 2026 (post 3), the anatomy of a citation-worthy methodology page (post 4), how to document priors as evidence (post 6), how to design a citation-worthy decision dashboard (post 7), and the four-stage publication framework that integrates all of it (post 10).
Frequently Asked Questions
What if my MMM uses frequentist methods rather than Bayesian?
Frequentist MMM can be rendered for citation, but the path is harder. The confidence-interval framing is statistically precise but linguistically unfriendly; LLMs trained on natural language interpret it inconsistently. The cleanest workaround is to publish the frequentist result alongside a plainer probabilistic framing (“the estimate sits in the range 1.6x to 2.7x with high confidence”). The Bayesian vs frequentist post in this series (Jul 16) covers the framing strategies in detail.
Will AI engines actually cite a methodology page from a private firm?
Yes, when the page passes the AAO gates. Citation behavior is driven by structural signals (schema, stable URL, methodology disclosure, source citations) rather than firm prestige. A small firm with a citation-worthy methodology page outperforms a large firm with a login-gated dashboard. The audit work is similar across firm sizes; the publishing discipline matters more than the budget.
Is the Discovery gate the right entry point for an MMM-focused site?
For most firms, yes. Discovery is the cheapest gate to pass and the precondition for every other gate. The Discovery Gate post (Tue Jun 30 in this series) walks through the five Discovery levers and the audit pattern. Pair it with this post for the methodology and MMM specific framing.
How long until citation behavior changes after publishing?
Two to six weeks for most engines. Perplexity tends to update fastest because it re-fetches per query. Claude and ChatGPT search update on slower cadences. Google AI Overviews can take four to six weeks. The methodology page is the foundation; once it lands and the structural signals pass, downstream citations follow as the engines re-index.
Where does this thread fit in the broader DSCRI ARGDW framework?
The AAO + MMM thread argues that measurement evidence is a specific content type that maps to specific gates more strongly than others. The 10-post Tuesday thread (running concurrently) covers the full 10-gate framework. The synthesis post on Sep 3 integrates both threads into a four-stage publication framework grounded in measurement evidence: generate evidence with explicit uncertainty, document priors and methodology auditably, publish results with structured data and stable URLs, and track downstream citations to update priors sequentially.
About the Author
Andrés Plashal
Author of the Assistive Agent Optimization (AAO) framework. Twenty years building search and measurement systems for B2B and SEC-regulated firms. Google Partner since 2017.
Credentials: UIUC Gies College of Business (Behavioral Science), Columbia College Chicago (Interactive Arts & Media). Member: American Marketing Association, GAABS, Paid Search Association. Published researcher (SCTE/NCTA).