Sample Sizes for Decision-Grade Channel Tests: Why Directional Signal Is a Trap
The Cost of Decision-Grade Certainty
The single most expensive line item in a properly structured channel validation budget is sample size. Statistical certainty is not free. The cost is the number of leads, calls, or conversions required to distinguish your historical baseline from your viability threshold with high enough confidence that the resulting decision is binary rather than ambiguous.
Most marketing teams do not run this calculation before launching a channel test. The result is the most common failure mode in marketing operations: a test that produces ambiguous data, no decision capacity, and a quarterly conversation that keeps producing decisions to extend.
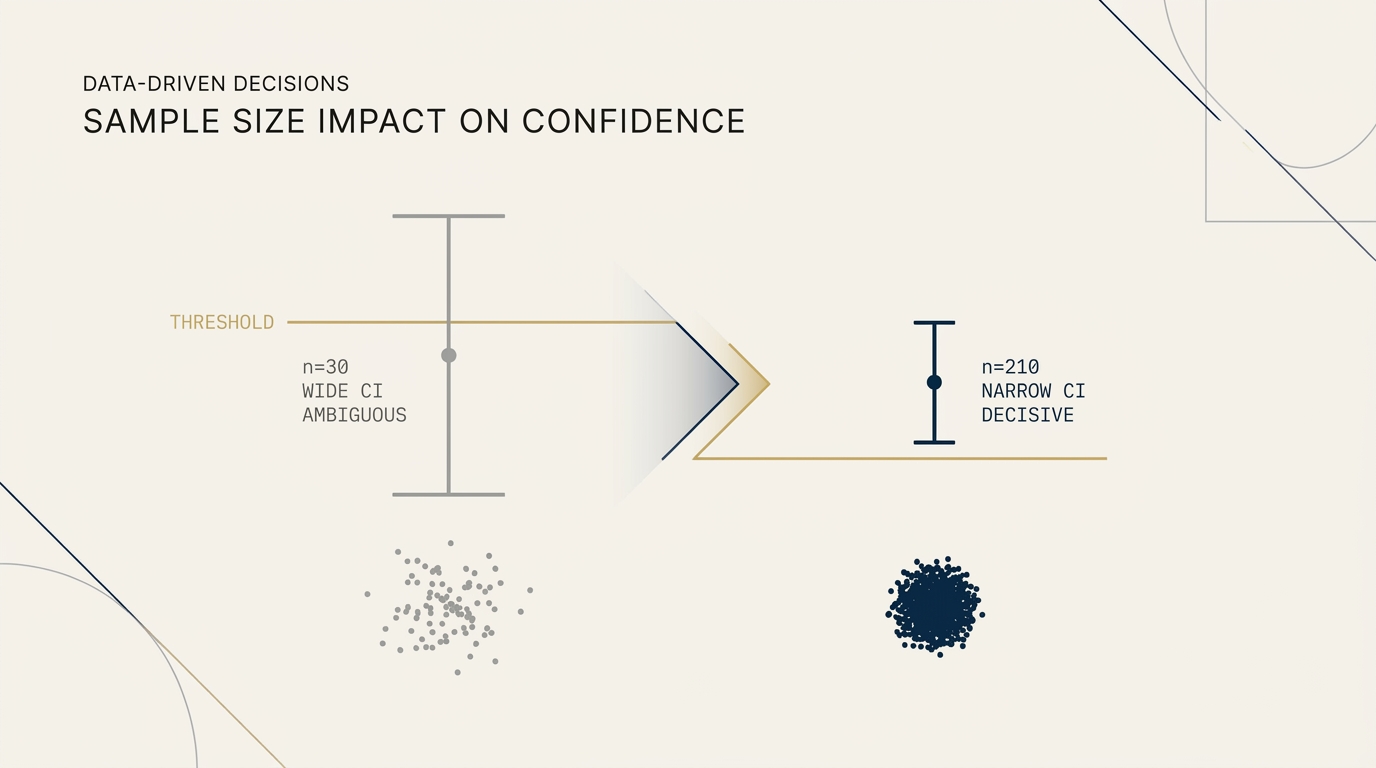
The mathematics is not exotic. It is a standard one-sample binomial proportion test against a fixed threshold. The Fleiss/Cohen formula gives the required sample size for distinguishing a baseline rate from a threshold rate at specified power and confidence levels. The output, applied to typical Pay-Per-Click (PPC) viability questions in advisory, is roughly 159 booked calls per channel under uncorrected single-test conditions, rising to approximately 210 calls per channel after Bonferroni correction for parallel multi-channel tests.
This is the number that should anchor your test budget. Without it, you are sizing the budget against intuition, and intuition systematically underestimates the sample required to produce a decision-grade result.
What the Numbers Actually Mean
The 159-call number is derived for a specific question: distinguishing a 4.3% historical baseline from a 10% threshold at 90% statistical power and 95% confidence. The 4.3% baseline is the documented historical close rate from a prior test, structurally aligned with the 4% industry baseline that SmartAsset’s published methodology discloses. The 10% threshold is the viability target set by the firm’s economics, anchored in the threshold-versus-forecast framing that defines the channel-decision math. The 90% power and 95% confidence are standard parameters for decision-grade business analysis.
Translated into operational terms, the sample size tells you how many actual booked calls have to accumulate in a single channel before you can confidently distinguish “this channel is performing at the historical baseline” from “this channel is performing at the viability threshold.” Below that sample, the confidence interval on the close rate is wide enough that both interpretations remain plausible.
At a per-call cost in the $1,200-$1,500 range, 159 calls represents roughly $190,000 to $240,000 of media spend per channel. After Bonferroni correction for parallel tests across three channels, the budget across all channels approaches three-quarters of a million dollars or more to produce decision-grade certainty on the channel viability question.
This is uncomfortable. It is also accurate. The discomfort is the cost of the certainty.
Why the Bonferroni Correction Matters
The Bonferroni correction is the technical move that distinguishes a competent parallel-channel test from a flawed one.
When you test three channels in parallel against the same viability threshold, you are running three independent statistical tests. Each test has a nominal 5% probability of producing a false positive (concluding the channel cleared the threshold when it actually did not). Across three independent tests, the probability of at least one false positive inflates to approximately 14% rather than 5%. The family-wise error rate is no longer controlled at the nominal level.
The Bonferroni correction restores control by dividing the nominal significance threshold by the number of parallel tests. Each test is now held to a stricter standard (approximately 1.67% per test for three parallel tests), which inflates the per-test sample size requirement by roughly 30-35% to maintain the same statistical power.
The practical effect is that the budget for a three-channel parallel test is materially larger than the budget for three sequential single-channel tests would imply. Most marketing teams running multi-channel tests are not running the Bonferroni adjustment. The result is tests that, even when they appear to clear the threshold, have a higher than acknowledged probability of being false positives.
The Tradeoff the Test Design Has to Accept
There is one tradeoff in this kind of test design that has to be acknowledged explicitly: the test sized to distinguish a 4% baseline from a 10% threshold is not sized to distinguish 7% from 10%. The 6-9% range is a statistically indistinguishable band at typical operating sample sizes.
Producing decision-grade certainty on that narrower band would require approximately 950 calls per channel after Bonferroni correction. At $1,200-$1,500 per call, that is north of $1 million per channel, or several million dollars across a parallel multi-channel test. The economics do not support it for most operating advisory firms.
The disciplined response to this tradeoff is to pre-commit that ambiguous outcomes (close rates landing in the 6-9% band) default to a kill decision rather than to “give it more time.” The reasoning is that the test was not sized to resolve the ambiguity, and extending the test horizon does not produce ambiguity-resolving data, because the underlying sample size constraint is structural rather than time-dependent.
I covered the kill-default rule in detail in a companion post on pre-committed gate triggers. The sample-size argument is the empirical reason the rule exists.
Why “Directional Signal” Tests Are a Trap
A frequent alternative to decision-grade sizing is a smaller “directional signal” test. The framing is that a 30-50 call test will give you enough signal to know whether the channel is worth a larger investment.
The framing is misleading. A 30-50 call test produces a confidence interval on the close rate so wide that most realistic outcomes fall inside it. The 95% confidence interval on 2 closes out of 30 calls spans roughly 1% to 22%. The same data is consistent with the channel performing well below the baseline, at the baseline, at the threshold, or significantly above the threshold. The “directional signal” is therefore not directional. It is noise.
The deeper problem is that a directional-signal test that produces an ambiguous result becomes an argument for a larger test, which is the test that should have been run in the first place. The cost of running both is higher than the cost of running the larger test directly. The directional signal frame is therefore a way of deferring the budget conversation, not avoiding it.
The economically rational move is to decide whether the channel viability question is worth answering at all. If it is, fund the decision-grade test. If it is not, do not fund the directional-signal test either. The middle option is the most expensive.
The Implication for Budget Conversations
Three operational implications follow.
Budget conversations have to start with the sample size. Before discussing creative, audience, channel mix, or vendor selection, the budget conversation has to settle whether the test is sized for decision-grade certainty or for directional signal. The two have different costs, different time horizons, and different decision outputs. Treating them as the same is the most common analytical error in test design.
The kill-default rule is the empirical complement to the sample-size constraint. Because the test is not sized to resolve ambiguous outcomes, ambiguous outcomes have to default to kill. This is not a preference; it is the operational consequence of the underlying math.
The number of parallel channels has to be bounded. Each additional parallel channel inflates the per-channel sample requirement through the Bonferroni correction. Testing seven channels in parallel produces a per-channel sample requirement substantially larger than the same test on three channels, even before the cross-channel attribution noise is considered. Most operating budgets cannot support more than two or three parallel channels at decision-grade sample sizes.
The Discipline
The discipline this asks for is to run the sample-size math before the test budget conversation, write the number down, and treat the resulting budget as the floor rather than as a starting point for negotiation.
The math is not negotiable. The budget required to produce a decision-grade answer on the channel viability question is what it is. A firm that runs the test at a smaller budget is not running a cheaper version of the same test. They are running a different test, one that produces directional signal rather than a decision, and the directional signal does not retire the question.
Most marketing teams have never run this calculation. The teams that have run it consistently produce better channel decisions, kill failed channels faster, and avoid the perpetual quarterly relitigation pattern that consumes most marketing operations attention. The math is one of the highest-leverage analytical practices I can recommend to any marketing operations function that has not adopted it yet.
About the Author
Andrés Plashal
Author of the Assistive Agent Optimization (AAO) framework. Twenty years building search and measurement systems for B2B and SEC-regulated firms. Google Partner since 2017.
Credentials: UIUC Gies College of Business (Behavioral Science), Columbia College Chicago (Interactive Arts & Media). Member: American Marketing Association, GAABS, Paid Search Association. Published researcher (SCTE/NCTA).